Ornith 1.0: The Open Source AI That Challenges Claude Opus 4.7
On June 25, 2026, DeepReinforce released Ornith-1.0, a family of open source AI models built for development agents. Its originality lies not in its size, but in its training method: instead of relying on an execution harness written by engineers, the model learns to build it itself for each task. And here’s the headline: DeepReinforce says its most powerful version outperforms Claude Opus 4.7 on two reference benchmarks. Here’s what we know.
Table of Contents
An AI That Builds Its Own Harness
Behind most coding agents is a key component: the harness (or scaffold). This is the code that surrounds the model and drives its work: it calls tools, runs commands and tests, collects results, handles errors, decides when to retry, and breaks the task into steps. It’s basically the pilot in the plane... By itself, the model only generates code.
With Ornith-1.0, the harness is no longer imposed from the start: the model learns to create it on its own while it learns to code. How? During training, the AI practices on thousands of tasks and receives a score each time based on the quality of the result, using a method called reinforcement learning (RL). Ornith’s novelty is that this score rewards not only the code produced, but also the way the model organizes itself to get there. After repeated attempts, the model retains the working methods that deliver the best results.
In its presentation paper, DeepReinforce calls this principle self-scaffolding: the AI develops its own way of operating.
Since the model’s main goal is to get a good score, it may be tempted to cheat to obtain it without really solving the problem: for example, by reading the validation tests in advance, or by writing the expected output directly without doing the work. This behavior is well documented and even has a name: reward hacking. It is a weakness of this training method. That said, DeepReinforce says it mitigates the issue with several safeguards designed to detect and block these bypass attempts.
Four Sizes, from Laptop to Datacenter
The Ornith-1.0 family comes in four versions: 9B Dense, 31B Dense, 35B MoE and 397B MoE. All are trained from Gemma 4 and Qwen 3.5, released under the MIT license and, according to the publisher, available without geographical restrictions. They offer a 256K token context window and can be connected notably to Claude Code and OpenHands.
Hardware positioning is a strong selling point:
- Ornith-1.0-9B is aimed at local use. It runs on a single GPU, whereas the heavier MoE versions need to be distributed across multiple cards. According to DeepReinforce, the model "fits on a single 80 GB GPU" (so yes, you still need serious hardware). I’ve already covered tools to find the right AI model for your PC or Mac.
- Ornith-1.0-397B is designed for demanding deployments, self-hosted to power an internal coding agent.
Note: Ornith-1.0 is based on Gemma 4, the open source family unveiled by Google in April 2026.
A Promising Scorecard for Ornith-1.0
According to DeepReinforce, Ornith-1.0-397B scores 77.5 on Terminal-Bench 2.1 and 82.4 on SWE-Bench Verified, ahead of Claude Opus 4.7 (70.3 and 80.8) and comparable open source models such as MiniMax M3 or DeepSeek-V4-Pro. The 35B version even reportedly beats Qwen 3.5-397B on Terminal-Bench 2.1, despite having far fewer parameters. Quite appealing on paper.
The chart published by DeepReinforce itself shows that Claude Opus 4.8 still holds the lead (85 on Terminal-Bench 2.1, 87.6 on SWE-Bench Verified), as does GLM-5.2-744B on the first benchmark. What matters is that, for coding, Ornith-1.0 appears to outperform other open source models.
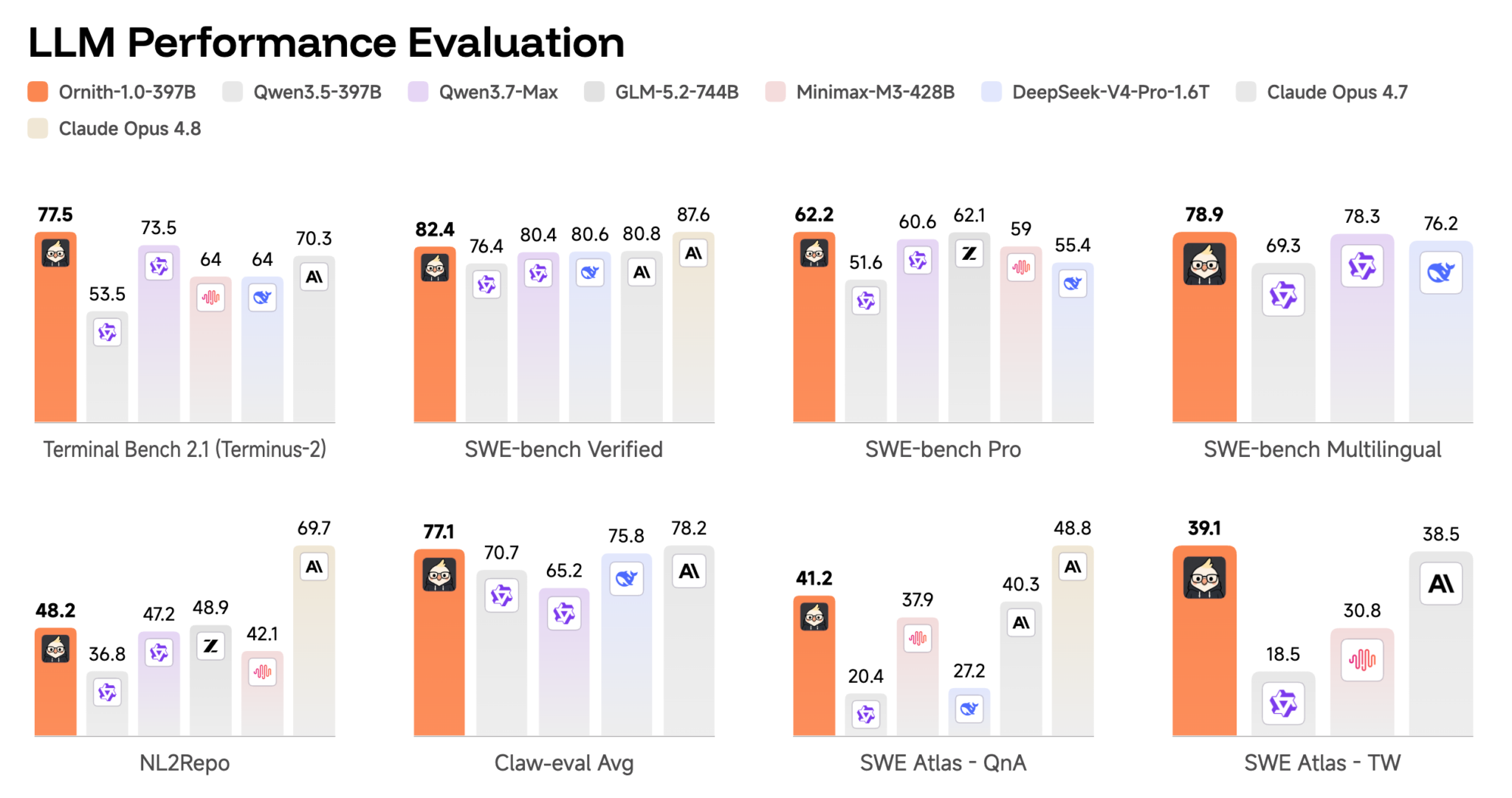
It is still important to understand what these tests measure. The two benchmarks highlighted by DeepReinforce evaluate very specific development skills, not general abilities:
- Terminal-Bench 2.1: a set of tasks to be completed in an isolated terminal (containerized environment), ranging from async code debugging to fixing security vulnerabilities.
- SWE-Bench Verified: the AI is given a real bug taken from an open source GitHub repository and must fix it without access to the test suite. The score corresponds to the percentage of bugs successfully resolved.
It has only been compared with Opus on development tasks, never on general reasoning, mathematics, writing, or multilingual use. Claude Opus is a general-purpose model, designed for a much broader range of use cases, whereas Ornith-1.0 is more task-specific. Beating Opus 4.7 on two code benchmarks therefore does not mean it does "everything better than Claude": the victory is real, but limited to a specific domain.
Useful links to explore the topic further:
- Ornith-1.0: Self-Scaffolding LLMs for Agentic Coding - DeepReinforce
- GitHub repository deepreinforce-ai/Ornith-1